
yeznable
[ kestra ] kestra vs Airflow 비교 실습 - (3) 워크플로우 본문
kestra와 airflow에서 가장 중요하다고 볼 수 있는 워크플로우 실습을 진행 해본다.
airflow는 찾아보면 정보가 많으니 글이 너무 길어지지 않게 간단히 언급만 하고 kestra 위주의 실습이 될듯 하다.
환경은 기존의 실습을 통해 준비 되어있다고 생각하고 진행한다.
[ kestra ] kestra vs Airflow 비교 실습 - (1) 설치
지난번에 아래 글을 통해 kestra를 간단하게 알아봤다. [ 맛보기 ] 현대적인 워크플로우 오케스트레이션 Kestra2015년에 출시했던 Airflow보다 현대적인 워크플로우 오케스트레이션이라는 Kestra 프로젝
yeznable-blog.tistory.com
API를 통해 데이터를 불러오고 해당 데이터를 파일로 S3에 저장하는 간단한 작업을 워크플로우로 만들어보자.
(기존 Terraform을 활용한 환경 설정을 따르지 않고 독자적으로 환경을 구성했다면 이 부분은 아마 건너 뛰어도 된다)
이번 실습에서는 kestra에서 S3를 활용하기 때문에 권한이 필요하다.
AWS에 로그인하고 kestra 리소스에서 활용하는 사용자를 [ IAM > 사용자 ] 에서 찾아 IAMFullAccess 권한을 추가 해줬다.
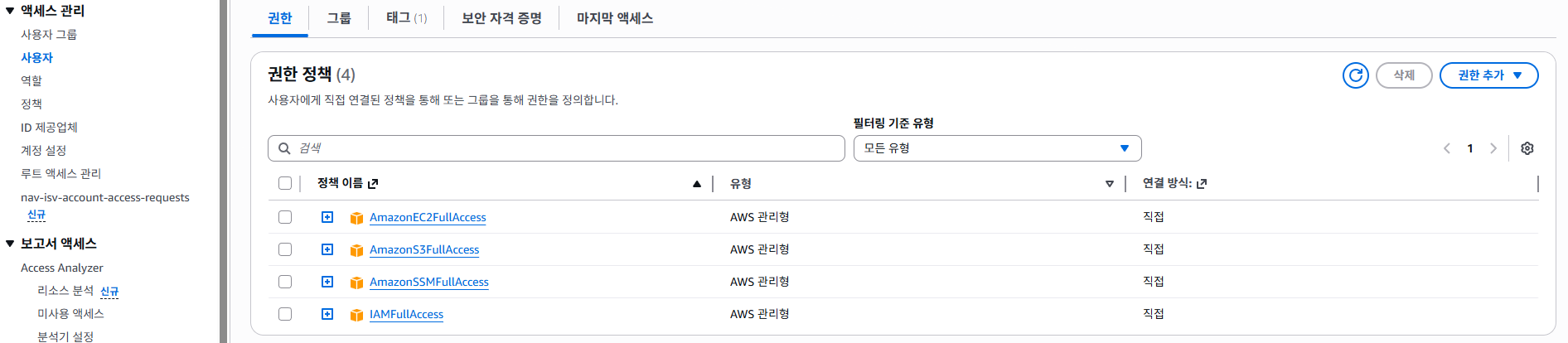
기존의 kestra 리소스를 관리하던 Terraform 디렉토리의 iam.tf 파일의 뒤쪽에 이렇게 추가 해준다.
~
locals {
s3_bucket_arn = "arn:aws:s3:::${var.s3_bucket_name}"
}
data "aws_iam_policy_document" "ssm_s3_access" {
# 버킷에 대한 List 권한
statement {
effect = "Allow"
actions = [
"s3:ListBucket",
]
resources = [
local.s3_bucket_arn
]
}
# 객체 단위 Get/Put/Delete 권한
statement {
effect = "Allow"
actions = [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject",
]
resources = [
"${local.s3_bucket_arn}/*"
]
}
}
resource "aws_iam_policy" "ssm_s3_access" {
name = "${var.name_prefix}_ssm_s3_access"
description = "Allow Kestra EC2 role to access S3 bucket ${var.s3_bucket_name}"
policy = data.aws_iam_policy_document.ssm_s3_access.json
}
resource "aws_iam_role_policy_attachment" "ssm_s3_access_attach" {
role = aws_iam_role.ssm_role.name
policy_arn = aws_iam_policy.ssm_s3_access.arn
}
그리고 variables.tf 뒤쪽에 이렇게 추가
~
variable "s3_bucket_name" {
description = "Kestra EC2가 접근할 S3 버킷 이름"
type = string
}
terraform.tfvars 뒤쪽에는 이렇게 추가 해준다.
여기에서 {생성한 버킷 이름}은 그대로 사용하는게 아니라 본인이 생성한 버킷의 이름을 넣어줘야 한다.
게임에서 닉네임 겹치면 안되듯이 유니크한 이름을 지정해야 버킷을 만들 수 있다.
~
s3_bucket_name = "{생성한 버킷 이름}"
S3 리소스를 준비하는 방법까지 이 글에 담으려니 너무 길어져서 생략한다.
검색하면 잘 나오고 어렵지 않다. 챗GPT나 제미나이도 잘 알려준다.
API 예시를 위해 간단히 불러올 데이터는 다음 링크를 사용한다.
https://catfact.ninja/fact
해당 링크를 호출하면 다음과 같이 고양이에 대해 랜덤한 사실을 json으로 뱉어준다.

Python 으로 API를 통해 값을 불러오는 건 requests 패키지를 활용해 다음과 같이 간단하게 작성할 수 있다.
import requests
url = "https://catfact.ninja/fact"
response = requests.get(url) # GET 요청
# 응답 코드 확인
print("Status code:", response.status_code)
# JSON 응답 파싱
data = response.json()
print(data) # 전체 JSON 출력
print(data["fact"]) # 고양이 정보(fact)만 출력
airflow에 위의 코드를 워크플로우 DAG로 만들려면 아래와 같이 작성할 수 있다.
이렇게 작성된 DAG를 dags/ 폴더에 저장하고 조금 기다리면 airflow의 DAGs 목록에 cat_fact_simple 항목이 뜬다.
개인적으로는 airflow에서 이런 식으로 워크플로우를 정의해야 하는게 불편했다.
내가 사용하던 버전에서는 DAG 형식이 잘못 작성되거나 하면 airflow가 갑자기 뻑나거나 그런 경우도 있었다.
from datetime import datetime
from airflow import DAG
from airflow.operators.python import PythonOperator
import requests
def fetch_cat_fact():
url = "https://catfact.ninja/fact"
response = requests.get(url) # GET 요청
print("Status code:", response.status_code)
data = response.json()
print("응답 전체:", data)
print("고양이 정보(fact):", data["fact"])
with DAG(
dag_id="cat_fact_simple",
start_date=datetime(2025, 1, 1),
schedule_interval=None, # 수동 실행용 (원하면 "0 * * * *" 같은 크론으로 변경)
catchup=False,
tags=["example", "cat"],
) as dag:
fetch_cat_fact_task = PythonOperator(
task_id="fetch_cat_fact",
python_callable=fetch_cat_fact,
)
kestra는 UI에서 직접 워크플로우를 만들 수 있다는 점이 airflow와 비교해서 큰 이점이라고 생각한다.
또한 airflow는 DAG를 Python만으로 작성할 수 있다는 것을 장점으로 하는데 Python으로 간단하게 할 수 있을만한 코드를 DAG로 바꿔 작성하다보면 불편해지는 경우가 많아서 장점이 조금 희석되는 느낌이 있다.
그러다보니 차라리 kestra처럼 Plugin을 많이 제공하는게 편할 수도 있겠다 싶었다.
kestra에서 API 호출 작업을 수행하는 워크플로우를 생성해보자
API 호출
좌측 메뉴의 Plugins 화면에 들어가서 requests라고 검색 해보면 관련 플러그인들이 나타난다.
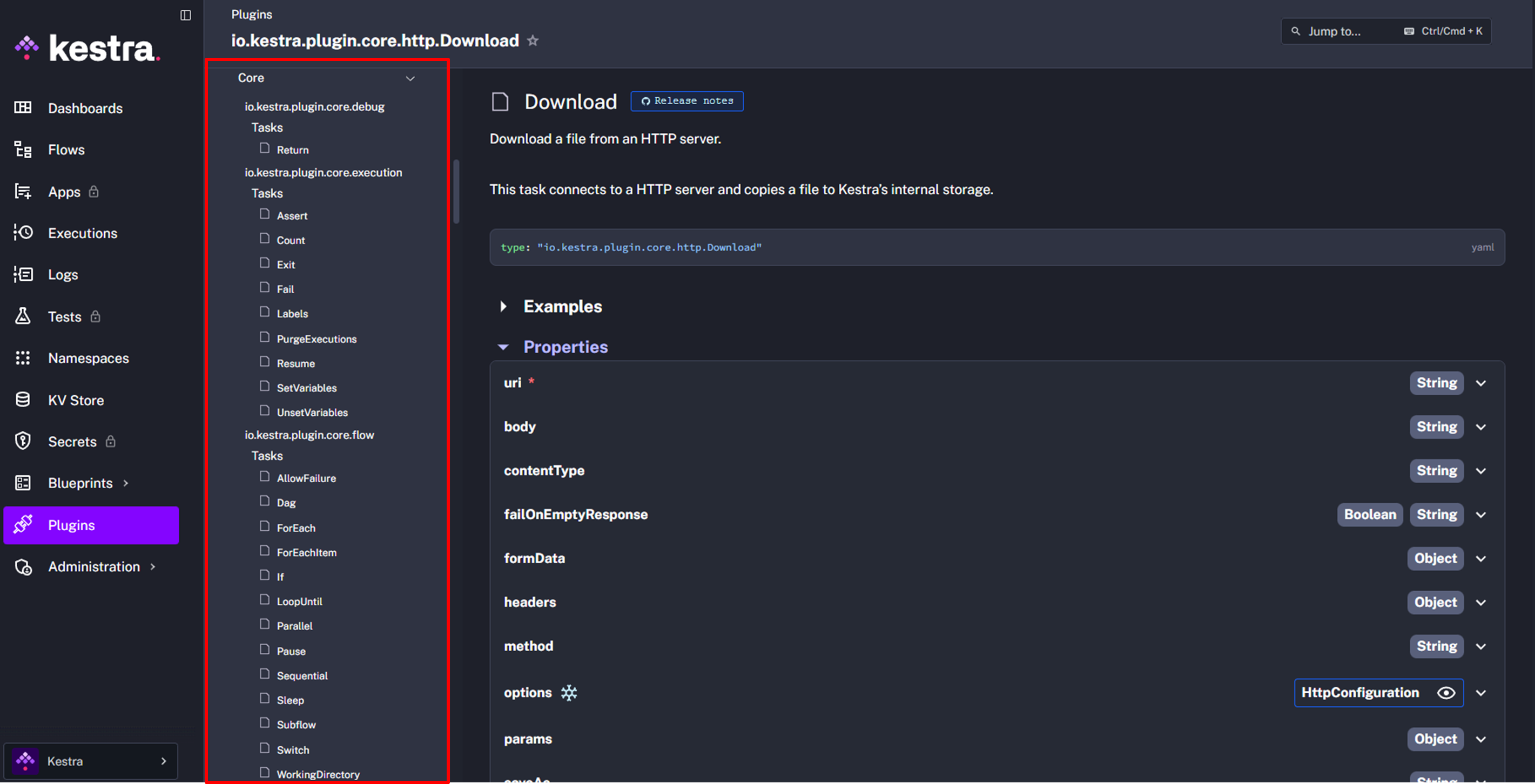
그 중에 지금 연관이 있어 보이는 것은 HTTP이니 들어가본다.

들어가보니 io.kestra.plugin.core.http.Download라는 항목이 나타난다.
설명을 읽어보니 내가 사용할 API에 맞는 항목은 아닌 것 같았다.
좌측 사진의 빨간 박스 부분을 스크롤하니 Request라는 항목이 있어 열고 Examples를 살폈다.
지금 상황에 쓸만한 간단한 예시가 있어서 복사 해뒀다.

좌측 메뉴의 Flows로 들어가 우측 상단의 Create 버튼으로 워크플로우를 생성할 수 있다.
Create 버튼을 눌러 나타난 화면의 Flow Code 창에 복사해둔 코드를 붙여넣는다.
id, namespace 등을 원하는 대로 바꾸고 uri도 사용할 API의 주소로 변경하고 우측 상단의 Save 버튼으로 저장한다.
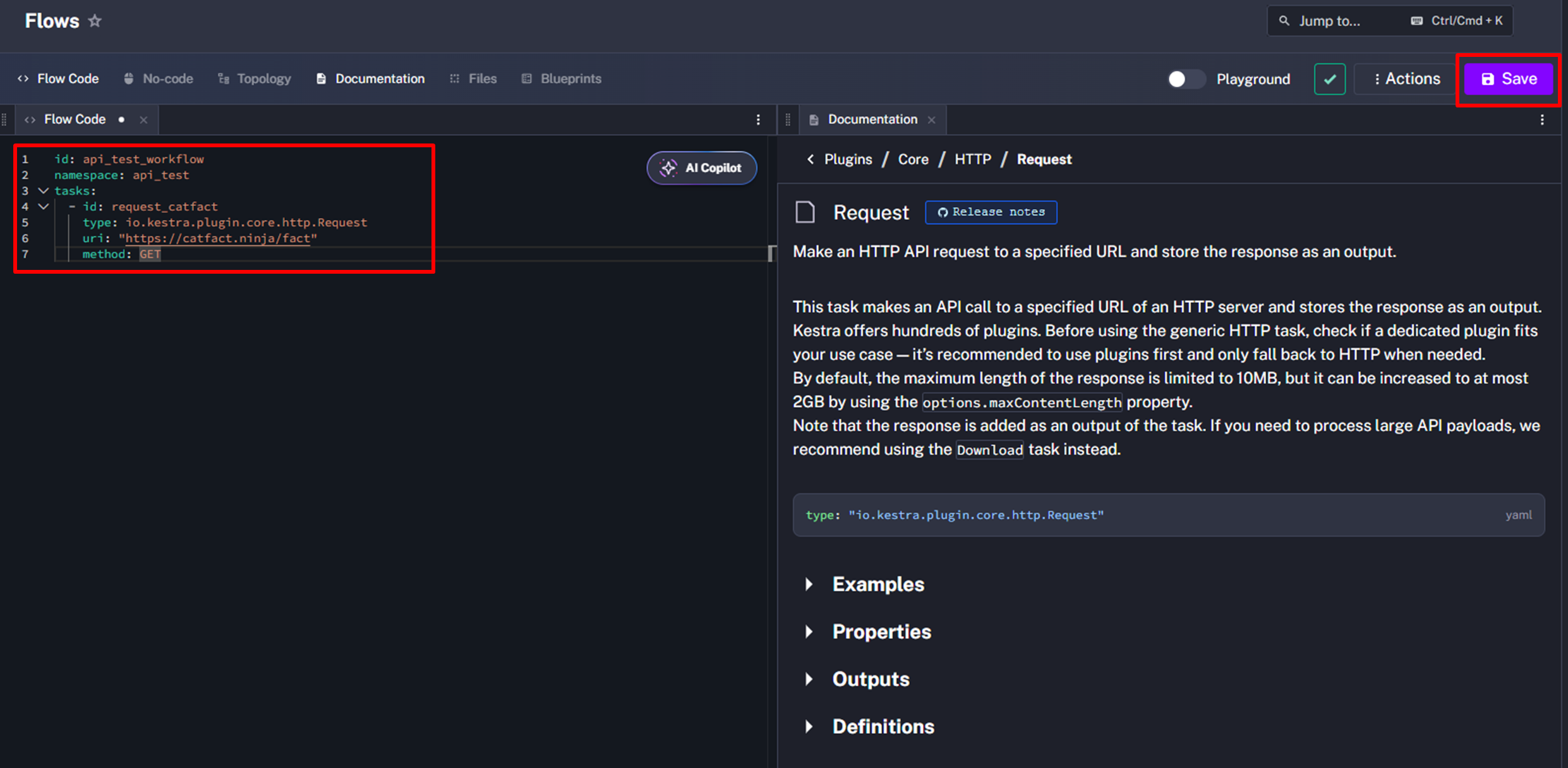
Flow가 저장되면서 해당 Flow 화면으로 이동이 된다. 우측 상단의 Execute 버튼을 눌러 실행할 수 있다.

실행을 시키면 Executions 화면으로 넘어온다.
실행이 잘 완료되면 다음과 같은 화면이 나타난다.

실패하면 이렇게 빨간 바로 표시가 되는데 해당 바를 클릭 해보면 로그를 확인할 수 있다.

성공한 Execution의 Outputs 탭에 들어가보면 api 호출 결과로 다음과 같은 메시지를 받은 것을 확인할 수 있다.

{
"fact":"Miacis, the primitive ancestor of cats, was a small, tree-living creature of the late Eocene period, some 45 to 50 million years ago."
,"length":133
}파일 저장
이번에는 해당 결과를 파일로 저장해보자.
Plugins 메뉴에서 write를 검색하니 Storage 항목이 있어 들어가봤다.
io.kestra.plugin.core.storage.Write 타입에 대한 예시를 다음과 같이 확인할 수 있다.

아까 만들었던 api_test_workflow 플로우에 적용하기 위해 [ Flows > api_test_workflow > Edit ] 경로로 들어가서 Flow Code 창에 task를 다음과 같이 추가 해준다.
id: api_test_workflow
namespace: api_test
tasks:
- id: request_catfact
type: io.kestra.plugin.core.http.Request
uri: "https://catfact.ninja/fact"
method: GET
- id: write_json
type: io.kestra.plugin.core.storage.Write
content: "{{ outputs.request_catfact.body }}"
extension: ".json"
2개의 작업을 실행한 결과는 간트 탭에서 이렇게 나타난다.
바에 마우스를 올리면 실행 시간도 확인할 수 있고 클릭하면 실행 로그를 확인할 수 있다.

[ Executions > 실행 기록 선택 > Output 탭 > write_json > uri ] 경로를 찾아가보면 다운로드, 프리뷰 버튼이 있다.

여기서 작성된 파일은 실제 파일시스템에 저장되는 파일은 아니라고 한다.
그래서 UI에서 다운로드 하지 않고 실제 파일을 떨구려면 S3나 MinIO 등의 경로에 떨궈야 한다.
S3에 업로드
Plugins에서 S3를 검색해서 io.kestra.plugin.aws.s3.Upload 타입의 태스크를 만들어야 한다는 것을 확인했다.
Flow Code를 다음과 같이 수정한다.
bucket에는 미리 생성해둔 S3 버킷의 이름을 넣는다.
key는 파일의 저장 경로, 이름 등을 지정하는데 실행 시간을 지정했다.
id: api_test_workflow
namespace: api_test
tasks:
- id: request_catfact
type: io.kestra.plugin.core.http.Request
uri: "https://catfact.ninja/fact"
method: GET
- id: write_json
type: io.kestra.plugin.core.storage.Write
content: "{{ outputs.request_catfact.body }}"
extension: ".json"
- id: upload_to_s3
type: io.kestra.plugin.aws.s3.Upload
from: "{{ outputs.write_json.uri }}"
bucket: "yeznable-kva-bucket-001"
key: "catfacts/{{ execution.startDate | date('yyyyMMdd_HHmmss', 'Asia/Seoul') }}.json"
region: "ap-northeast-2"
저장하고 Topology 탭에 들어가니 태스크들이 도식화된 결과를 볼 수 다.
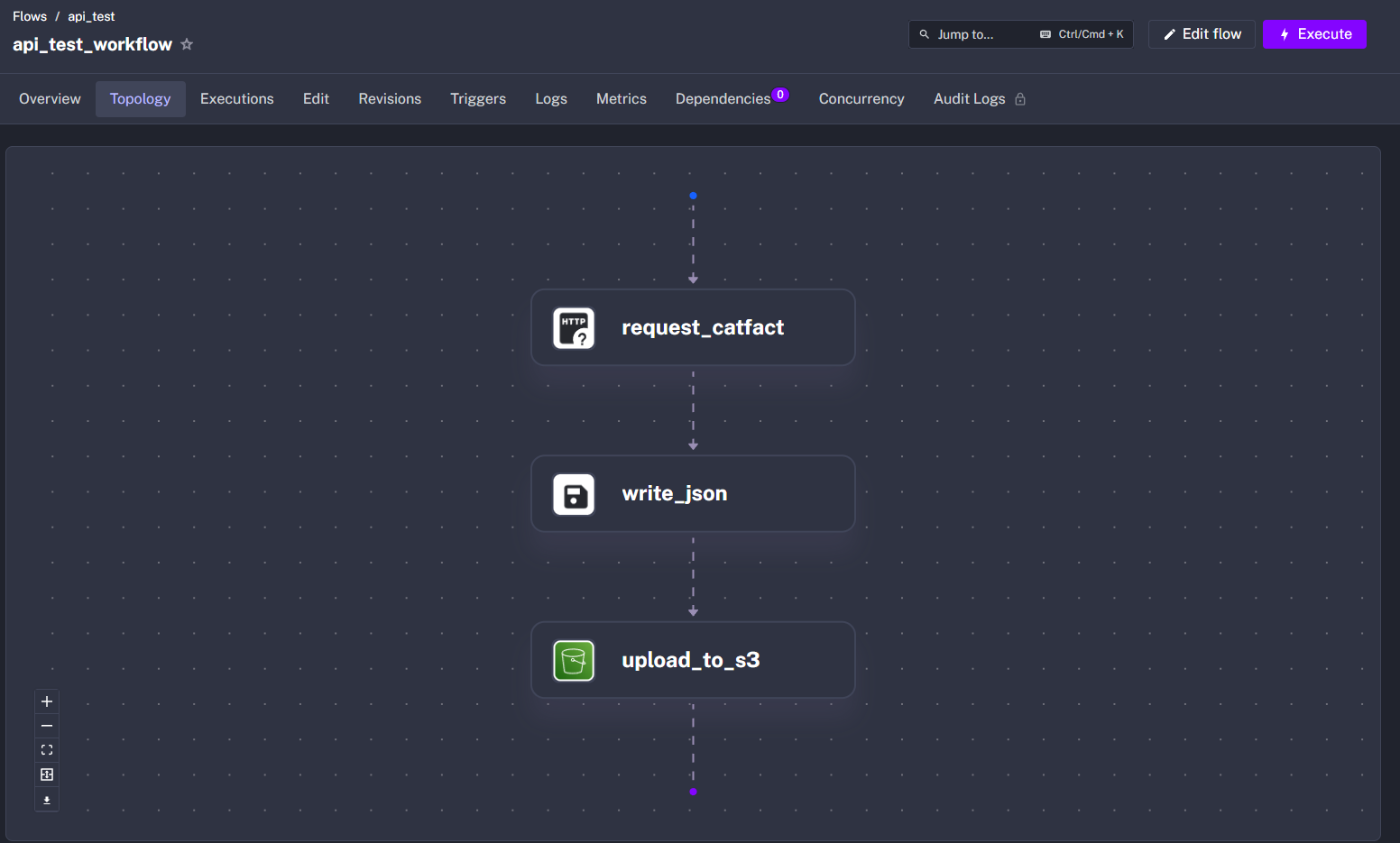
실행하니 잘 완료되었고 S3에 접속 해보니 파일이 제대로 업로드 되어 있다.

파일 변환 후 저장
json이 아닌 parquet 파일로 저장하고 싶다면 Python 태스크를 추가해 환 후 업로드할 수 있다.
Python 코드를 실행할 때 사용할 플러그인 타입은 io.kestra.plugin.scripts.python.Script이다.
beforeCommands에서 필요한 패키지를 설치할 수 있고 설치 시간을 아끼려면 미리 설치해둔 docker 이미지를 불러와 사용할 수도 있다.
write_json 태스크를 빼고 to_parquet 태스크를 추가해 다음과 같이 Flow Code를 수정한다.
id: api_test_workflow
namespace: api_test
tasks:
- id: request_catfact
type: io.kestra.plugin.core.http.Request
uri: "https://catfact.ninja/fact"
method: GET
- id: to_parquet
type: io.kestra.plugin.scripts.python.Script
beforeCommands:
- pip install pandas pyarrow
outputFiles:
- "*.parquet"
script: |
import pandas as pd
import json
data = json.loads("""{{ outputs.request_catfact.body }}""")
df = pd.DataFrame([data])
df.to_parquet("catfact.parquet", index=False)
- id: upload_to_s3
type: io.kestra.plugin.aws.s3.Upload
from: "{{ outputs.to_parquet.outputFiles['catfact.parquet'] }}"
bucket: "yeznable-kva-bucket-001"
key: "catfacts/{{ execution.startDate | date('yyyyMMdd_HHmmss', 'Asia/Seoul') }}.json"
region: "ap-northeast-2"
실행 후 S3 버킷에 들어가보면 parquet 파일이 잘 저장된 것을 확인할 수 있다.

실습 후기
kestra의 워크플로우를 API 호출, 데이터 저장, Python을 활용한 데이터 변환, S3 업로드 기능으로 간단하게 실습 해봤다.
실습을 진행하며 다음과 같은 인상을 받았다.
1. Airflow는 DAG를 따로 작성해야 하는데 kestra는 UI에서 Flow Code를 바로 작성 할 수 있으니 편하다.
2. Airflow는 DAG를 잘못 작성하면 뻗어버리는데 kestra는 잘못 작성할 것 같으면 알려준다.
3. Python을 잘 쓰던 사람이 kestra 플러그인을 다시 익히려면 귀찮고 굳이 이 도구를 써야 하나 싶을 수도 있겠다.
4. 오히려 개발자가 아니라면 코드를 짜는 것보다 자주 쓰는 플러그인 사용법만 익히면 접근성이 쉬울 수도 있겠다.
다음에는 트리거에 대해 실습 해볼까 한다.
airflow는 정해진 스케줄대로만 워크플로우를 실행시킬 수 있는 한편 kestra는 이벤트를 기준으로 작업을 트리거 시킬 수 있어 실시간 처리에 좋다고 한다.
'하는 일 > 데이터엔지니어링' 카테고리의 다른 글
| [ MySQL ] JSON_TABLE 함수 (0) | 2025.11.25 |
|---|---|
| [ kestra ] kestra vs Airflow 비교 실습 - (2) UI (0) | 2025.11.21 |
| [ kestra ] kestra vs Airflow 비교 실습 - (1) 설치 (0) | 2025.11.21 |
| [ Terraform ] Docker 활용 리소스 템플릿 만들어두기 (0) | 2025.11.20 |
| [ 사회생활 ] 오지랖을 부렸다 (0) | 2025.11.19 |
