
yeznable
[ 따라잡기 ] DuckDB + DBT 데이터 파이프라인 만들기 (1) - DuckDB 본문
우선 아래 두 링크의 글을 매우 많이 참고하고 따라하면서 많이 배웠음을 밝힌다.
첨부한 링크 뿐만 아니라 블로그에 있는 글들이 모두 많은 도움이 된다.
DuckDB 사용법(DuckDB Python + Jupyter Lab)
이 글은 DuckDB 사용법을 작성한 글입니다 예상 독자 DuckDB가 궁금하신 분 데이터 분석가 : Pandas가 느리다고 생각해서 다른 대안을 찾고 있는 분 데이터 엔지니어 : 데이터 엔지니어링의 Transform 영
zzsza.github.io
로컬 초경량 프로젝트 (DBT, DuckDB)
DBT를 배웠으니, 이제 로컬에서 한번 가볍게 데이터 파이프라인을 만들어보겠습니다. 물론, 스케줄링이 붙지않아 자동화되지 않겠지만, 추후에 에어플로우와 함께 프로젝트를 진행해보겠습니다
velog.io
요즘은 데이터 구조가 데이터레이크, 데이터레이크하우스 같은 형식으로 발전해야 한다는 아티클을 많이 읽었는데 그때마다 아이스버그, 빅쿼리 또는 레드시프트 같은 서비스들 얘기가 나와서 돈을 많이 들여야만 경험할 수 있는거라고 생각했다.
그 중간중간에 DuckDB에 대한 이야기도 분명 있었을텐데 잘 모르는 기술이라서 흘려넘겼던 것 같다.
내가 이해하기로 데이터레이크는 기존의 ETL 과정을 ELT 과정으로 바꾸는 핵심적인 개념이다.
기존의 ETL 과정을 내가 경험했던 케이스로 정리하면 다음과 같다.
[ ETL ]
Extract(추출)
: 크롤링으로 수집된 데이터 또는 서비스의 로그들이 파일로 떨어지거나 Kafka를 통해 발생됨
Transform(변환)
: 파이썬 스크립트나 아파치 스파크로 발생(추출)된 데이터를 읽어 DB에 저장하기 좋은 형태로 변환
Load(저장)
: 변환 과정의 끝에 DB에 저장됨
이걸 ELT로 전환한다는 건 다음과 같다.
[ ELT ]
Extract(추출)
: 크롤링으로 수집된 데이터 또는 서비스의 로그들이 발생
Load(저장)
: 발생된 데이터를 파일로 저장
Transform(변환)
: 필요할 때 파일에서 데이터를 읽어 바로 원하는 형태로 변환해서 사용
사실 ETL에 익숙한 내가 ELT나 데이터레이크 개념으로 생각을 전환하는게 쉽지 않다.
회사에서 레드시프트를 도입해보려고 했을 때도 ELT 개념이 잡혀있지 않아서 파일에서 데이터를 바로 쿼리한다는 생각을 못했다(AWS는 또 이런거 하려면 다른 서비스 이것저것 같이 써야 해서 불편하다).
그냥 레드시프트는 데이터를 아무리 많이 넣어도 인덱스 없이 원하는 쿼리를 마음껏 날릴 수 있고 빠르게 실행된다(돈만 충분하다면) 이렇게 알고 있었다.
이번에 DuckDB로 경량 또는 개인 데이터레이크를 구현할 수 있다는 것을 알게 되었고 사용하면서 ELT를 어느정도 이해할 수 있게 된 것 같다.
DuckDB가 무엇인가에 대해서기술적으로 아직 더 공부해야 할것 같지만 개념은 다음 링크가 잘 설명해줄 수 있는 것 같다.
DuckDB: 개인용 DataLake로 데이터 분석 혁명을 시작해보세요
현대 데이터 분석의 패러다임은 급격한 변화를 겪고 있으며, 이러한 변화의 중심에는 DuckDB가 자리하고 있습니다. 특히 Google의 Jordan Tigani가 'big data is dead'라고 선언한 이후, DuckDB는 데이터 분석
digitalbourgeois.tistory.com
위에 적어놓은 링크들에 좋은 내용들은 다 쓰여있으니 나는 내 실습 경험을 바로 남긴다.
회사에서 윈도우를 써서 다음 방법으로 DuckDB를 먼저 설치했다.
MAC과 리눅스 설치 방법은 위의 첫번째 링크에 있다.
# 윈도우 CMD에서 실행
winget install DuckDB.cli
설치가 완료되면 CMD에서 duckdb 명령어로 다음과 같이 데이터베이스에 접근할 수 있다.
DuckDB를 기본 설정으로 실행하면 아래 캡쳐에 빨간색으로 쓰인 것처럼 in-memory 데이터베이스에 연결이 된다.
그 말은 데이터베이스에 접근해서 다음과 같이 테이블을 만들고 나갔다가 다시 들어가면 DB의 내용이 없어진다는 것이다.
# 디렉토리의 파일 리스트 조회
dir /b
# DuckDB 실행
duckdb
# 테이블을 만들고 데이터 조회
create table tb_test as select 1 as i;
select * from tb_test;
# CTRL+C 로 DuckDB 종료
# 다시 DuckDB 실행
duckdb
# 아까 만든 테이블의 데이터 조회
select * from tb_test;
# 에러 발생을 확인하고 CTRL+C로 DuckDB 종료
# 디렉토리의 파일 리스트 조회해서 변경 없는 것 확인
dir /b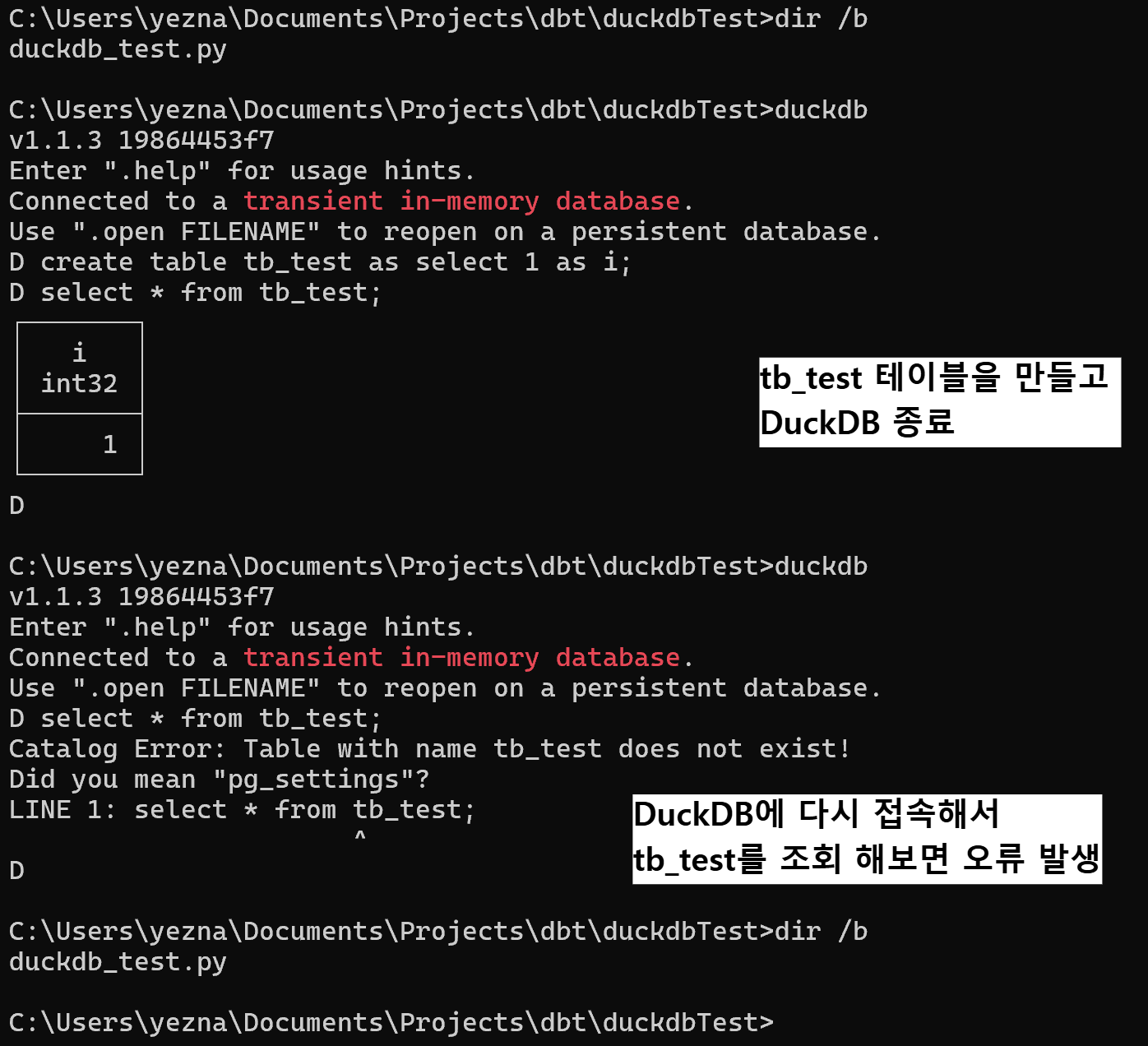
데이터가 날아가는게 무슨 데이터베이스냐 싶지만 duckdb 명령어 뒤에 데이터베이스 이름을 적으면 파일로 저장해서 데이터를 유지할 수 있다.
이때 생성된 testdb.duckdb라는 파일 하나가 데이터를 가지고 있는 데이터베이스이다.
이 파일 하나만 삭제하면 데이터베이스가 삭제되는 거고 이 파일 하나만 전달되면 데이터베이스가 이전되는 거라고 볼 수 있다.
# 디렉토리의 파일 리스트 조회
dir /b
# testdb.duckdb라는 파일명 파라미터를 전달하며 DuckDB 실행
duckdb testdb.duckdb
# 테이블을 만들고 데이터 조회
create table tb_test as select 1 as i;
select * from tb_test;
# CTRL+C 로 DuckDB 종료
# 다시 파일명을 지정하여 DuckDB 실행
duckdb testdb.duckdb
# 아까 만든 테이블의 데이터 조회
select * from tb_test;
# 에러 없이 조회되는 것을 확인하고 CTRL+C로 DuckDB 종료
# 디렉토리의 파일 리스트 조회해서 testdb.duckdb 파일이 만들어진 것 확인
dir /b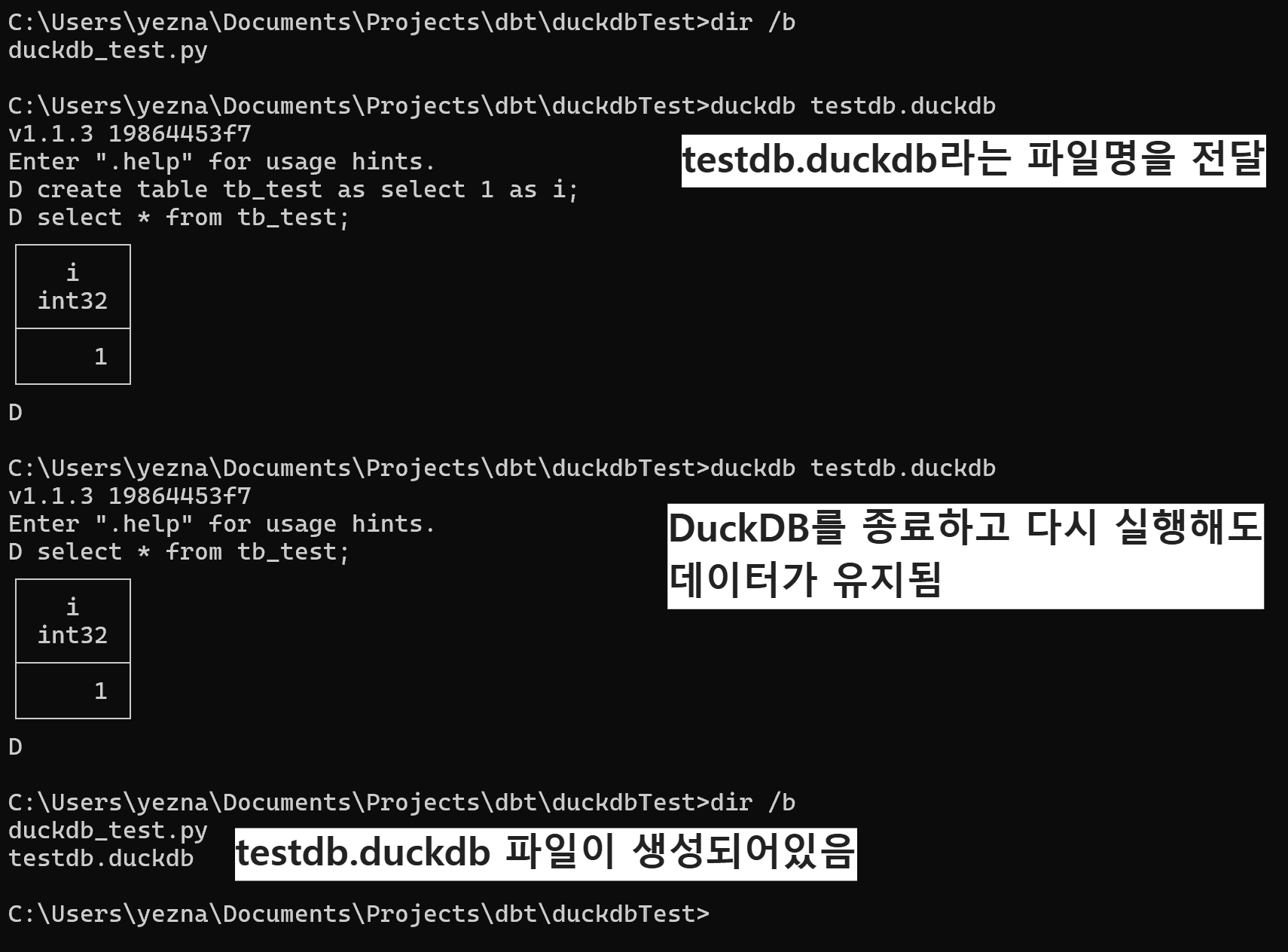
DuckDB는 DBeaver 에디터에서 연결해서 사용할 수 있다.
DBeaver는 다음 링크에서 다운로드 받을 수 있다.
Download | DBeaver Community
Download DBeaver Community 24.3.4 Released on February 2nd 2025 (Milestones). It is free and open source (license). Also you can get it from the GitHub mirror. System requirements. DBeaver PRO 24.3 Released on December 16th, 2024 PRO version website: dbeav
dbeaver.io
DBeaver에서 커넥션을 만들 때 아래로 조금 내려보면 오리 머리에 부리가 달린듯한 아이콘의 DuckDB를 찾을 수 있다.

DuckDB 커넥터를 선택하면 다음과 같은 화면으로 넘어가서 Open으로 아까 생성된 파일을 선택하면 DB에 연결된다.

처음 연결할 때는 왼쪽과 같이 드라이버를 설치하라고 한다.
설치를 마치면 오른쪽과 같이 tb_test 테이블이 생성된 testdb로의 연결이 만들어진다.


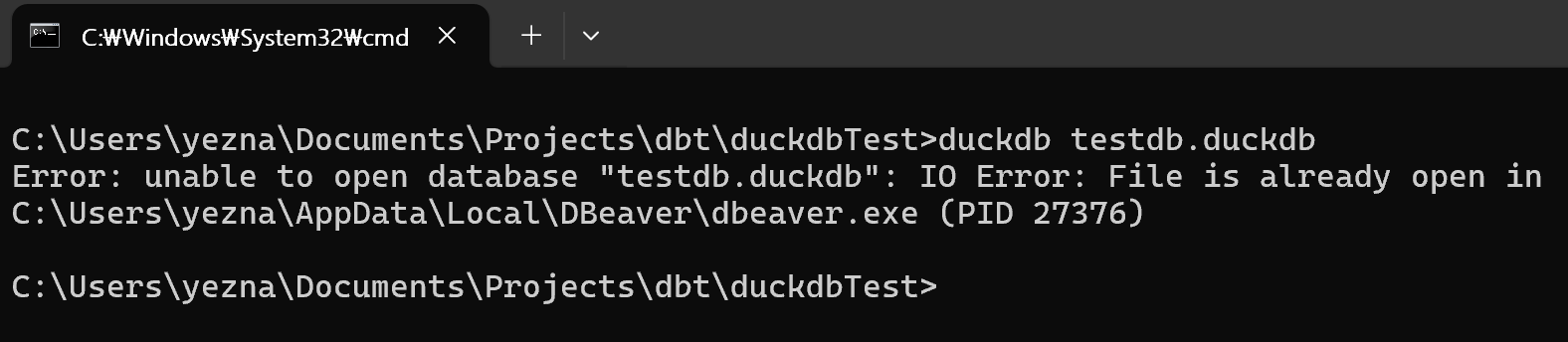
DuckDB의 불편한 점이지만 원래 만들어진 프로세스 기반 데이터베이스라는 의도에 따라 DBeaver에 연결되어있을 때는 CMD에서 해당 데이터베이스에 접속할 수 없다.
그 반대로 CMD에 접속해있을 때도 DBeaver에서 커넥션 생성에 실패한다.
하지만 해당 파일이 아닌 in-memory 데이터베이스나 다른 파일의 데이터베이스에는 접속할 수 있다.
파이썬에서 DuckDB에 연결할 때는 다음 두개의 방법으로 패키지 설치를 할 수 있다.
나는 이후에 DuckDB와 DBT를 연결해 활용할 생각을 하고 있어서 후자의 방법으로 설치했다.
# 방법1. duckdb만 설치
pip install duckdb
# 방법2. dbt 관련 패키지들과 함께 설치
pip install dbt-core dbt-duckdb
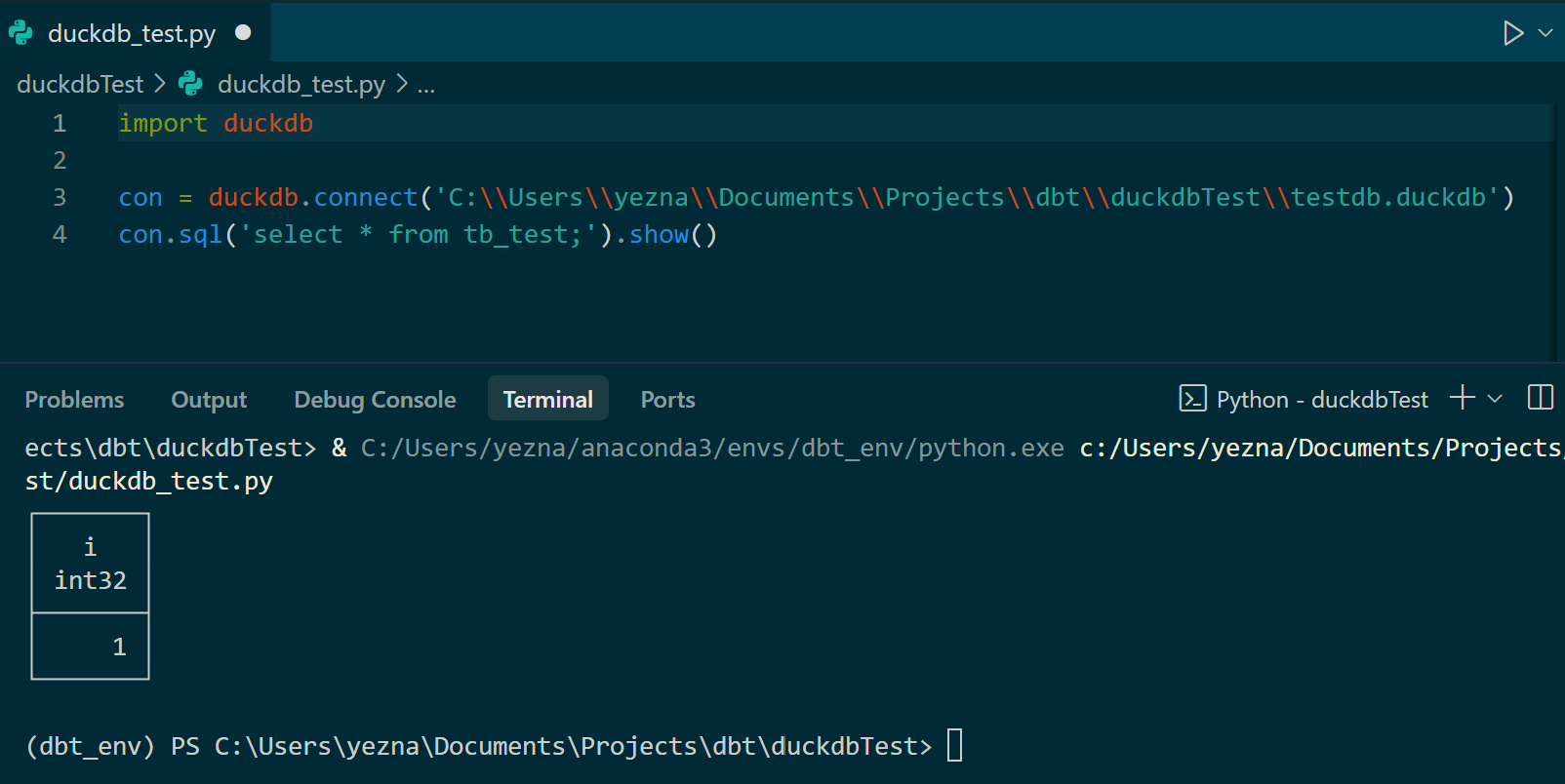
스크립트를 만들어 아까 생성한 파일에 접속할 수 있다.
마찬가지로 DBeaver 또는 CMD에서 해당 파일의 데이터베이스로 접속하고 있으면 스크립트 실행에 오류가 발생한다.
DuckDB를 써보면서 ELT에 대해 이해할 수 있었다고 했는데 그 이유는 다음과 같다.
다음 링크에서 데이터를 받아서 활용한다.(로그인이 필요하다)
TFT(League Of Legends) - High Elo Ranked Games
Challenger, GrandMaster, Master, Diamond, Platinum 10000 Game Datasets each
www.kaggle.com
다음과 같이 쿼리에서 from절에 파일 경로를 지정하면 DB에 데이터를 입력하는 과정 없이 바로 파일에 쿼리할 수 있다.
속도도 매우 빠르다.

'하는 일 > 데이터엔지니어링' 카테고리의 다른 글
| [ 따라잡기 ] DuckDB + DBT 데이터 파이프라인 만들기 (3) - DBT Models (0) | 2025.02.07 |
|---|---|
| [ 따라잡기 ] DuckDB + DBT 데이터 파이프라인 만들기 (2) - DBT (0) | 2025.02.07 |
| [Medium 아티클] Data Landscape Trand 2024-2025 (0) | 2025.02.04 |
| [아티클] 최근 관심있는 분야의 글이 많은 블로그 (0) | 2025.01.21 |
| [ 따라잡기 ] Crawlee and Playwright with Python - Crawlee 설치 (0) | 2025.01.15 |


