
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터베이스
- 행궁동
- duckdb
- 데이터엔지니어링
- 그래피티
- 티스토리챌린지
- 스티커
- AI
- 수원
- 독서
- 클릭하우스
- Advanced
- db
- Python
- 인문
- 맛집
- SQL
- mysql
- query
- 취미
- Playwright
- 책
- 오블완
- dbt
- Database
- crawlee
- 낙서
- clickhouse
- 윈드서프
- 스트릿
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 데이터베이스
- 행궁동
- duckdb
- 데이터엔지니어링
- 그래피티
- 티스토리챌린지
- 스티커
- AI
- 수원
- 독서
- 클릭하우스
- Advanced
- db
- Python
- 인문
- 맛집
- SQL
- mysql
- query
- 취미
- Playwright
- 책
- 오블완
- dbt
- Database
- crawlee
- 낙서
- clickhouse
- 윈드서프
- 스트릿
- Today
- Total
yeznable
[ 따라잡기 ] DuckDB + DBT 데이터 파이프라인 만들기 (2) - DBT 본문
아래 두 링크의 글을 매우 많이 참고하고 따라하면서 많이 배웠음을 밝힌다.
첨부한 링크 뿐만 아니라 블로그에 있는 글들이 모두 많은 도움이 된다.
DuckDB 사용법(DuckDB Python + Jupyter Lab)
이 글은 DuckDB 사용법을 작성한 글입니다 예상 독자 DuckDB가 궁금하신 분 데이터 분석가 : Pandas가 느리다고 생각해서 다른 대안을 찾고 있는 분 데이터 엔지니어 : 데이터 엔지니어링의 Transform 영
zzsza.github.io
로컬 초경량 프로젝트 (DBT, DuckDB)
DBT를 배웠으니, 이제 로컬에서 한번 가볍게 데이터 파이프라인을 만들어보겠습니다. 물론, 스케줄링이 붙지않아 자동화되지 않겠지만, 추후에 에어플로우와 함께 프로젝트를 진행해보겠습니다
velog.io
지난 포스팅에서 DuckDB에 대해 다뤘고 이번에는 DuckDB와 함께 DBT를 경험해본 내용을 남긴다.
DuckDB와 파이썬 스크립트 및 에어플로우만으로도 데이터레이크를 만들 수 있지만 DBT는 이를 훨씬 편하고 효율적으로 만들어주는 프레임워크 느낌이다.
[ 설치 및 프로젝트 준비 ]
DuckDB가 이미 설치되어있다는 것을 가정하고 다음과 같이 환경을 준비한다.
# 관리하기 용이하게 가상환경 만들기
conda create -n dbt_duckdb_env python=3.11
# 가상환경 활성화
conda activate dbt_duckdb_env
# dbt 설치
pip install dbt-core dbt-duckdb
dbt 환경을 처음 만들 때는 원하는 프로젝트 위치에 가서 init 명령어를 사용한다.
dbt init
그러면 프로젝트 이름을 입력하라고 뜬다.

프로젝트 이름을 입력하고 엔터하면 다음과 같이 어떤 데이터베이스를 사용할거냐는 질문이 나오는데 dbt-duckdb밖에 설치하지 않았으니 duckdb가 1번으로 나와있어서 1을 입력하고 엔터했다.
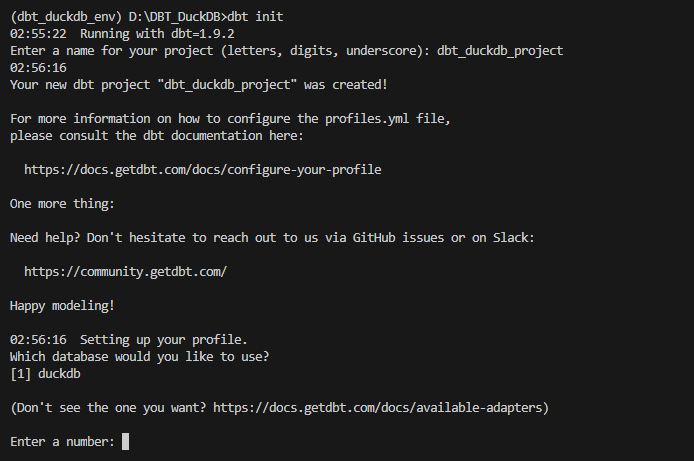
그러고나면 dbt init을 실행했던 위치에 입력했던 프로젝트명의 폴더와 logs 폴더가 생성되어있다.
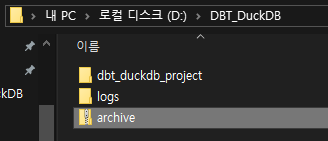
archive 파일은 데이터를 준비해둔 것으로 저번보다 큰 데이터를 준비했다.
다음 링크에서 받을 수 있다.
Yelp Dataset
A trove of reviews, businesses, users, tips, and check-in data!
www.kaggle.com
만들어진 프로젝트의 구조는 다음과 같다.
나도 아직 모든 구조의 역할들을 다 써보지는 못했다.
최상단의 두번째 링크(로컬 초경량 프로젝트)에서 dbt관련 글들을 보면 각 역할에 대해 알 수 있다.
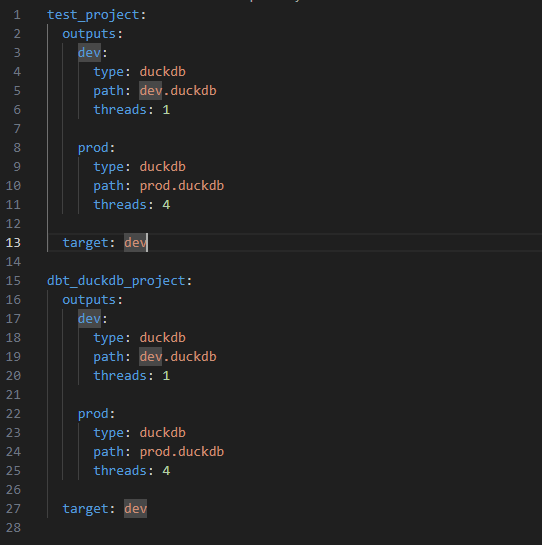
그리고 dbt init을 실행했다면 C:\Users\{사용자ID}\.dbt 경로에 profiles.yml 파일이 생성된다.
파일을 열어보면 나는 이전에 test_project라는 프로젝트를 생성한적이 있어서 이미 작성된 내용이 있고 방금 init 한 dbt_duckdb_project에 대한 정보가 정의되어있다.
생성한 프로젝트에서 dbt 작업을 실행시키려면 init을 한 위치에서 프로젝트 위치로 들어가야 한다.
# 경로 이동
cd dbt_duckdb_project
# dbt 실행
dbt run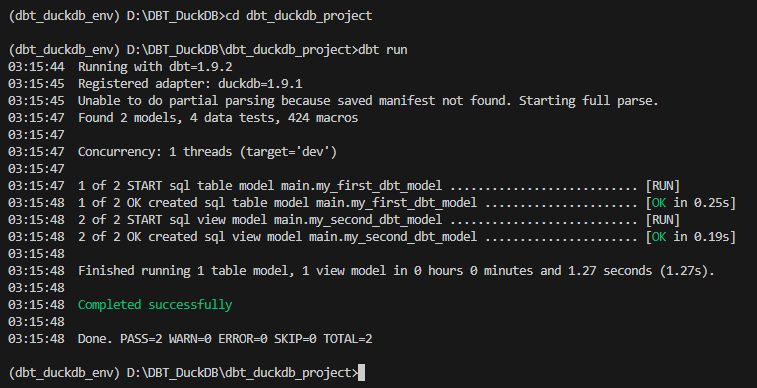
dbt run을 실행했더니 example 모델들에 대한 작업이 실행되었고 profiles.yml의 out에 정의된 대로 duckdb 파일이 생성되었다. C:\Users\{사용자ID}\.dbt\profiles.yml 파일에 target을 prod로 변경해서 run 하면 prod.duckdb 파일이 생성된다.
참고한 블로그에서는 프로젝트 위치의 dbt_project.yml에서 profile과 name의 이름이 다르도록 수정하는게 좋다고 하는데 아마 여러 프로젝트에서 같은 프로필을 공유하려고 그러는게 아닌가 싶다.
다음과 같이 3곳의 dbt_duckdb_project였던 이름을 first_project로 변경해줬다.

[ 모델 만들기 ]
DBT에서 모델은 결과만 놓고 보면 테이블을 만들어주는 기능을 한다.
그냥 DuckDB로 테이블을 create해서 데이터를 insert하는 것보다 모델로 만들면 해당 테이블의 데이터가 어떻게 구성 및 정의되는지 알 수 있고 dbt 문서 생성 시 해당 모델의 상세 내용 및 데이터 의존성을 확인할 수 있다.
모델은 용도에 따라 디렉토리를 구분해서 사용하면 좋다고 한다.
dbt에서 가이드로 주고 있는 형태는 다음과 같다.
staging : 초기 정제
intermediate : 중간 집계나 조인
mart : 최종 분석용 테이블
이에 맞춰서 first_project/models/ 경로에 stg, mid, mrt (staging, intermediate, mart 다 쓰기엔 너무 길어서..) 디렉토리를 추가했다.

스테이징 모델을 만들기 위해 데이터를 확인해본다.
데이터가 있는 위치에서 CMD를 열어 다음과 같이 조회했다.
# DuckDB in-memory 모드 실행
duckdb
# json파일에서 데이터를 바로 조회
describe select * from read_json('yelp_academic_dataset_user.json');
해당 데이터를 조회해서 stg_user라는 모델을 만들어보겠다.
first_project/model/stg/ 경로에 stg_user.sql 파일을 만들고 다음과 같이 작성한다.
{{ config(
schema='stg',
materialized='table'
) }}
WITH yelp_academic_dataset_user AS (
select *
from read_json('D:\\DBT_DuckDB\\data\\yelp_academic_dataset_user.json')
)
SELECT *
FROM yelp_academic_dataset_user
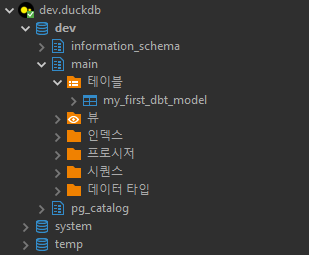
dbt run 하기 전의 DB 상태는 DBeaver로 봤을 때 다음과 같다.
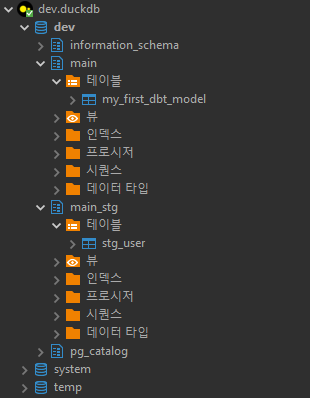
main 스키마의 my_first_dbt_model 테이블은 아까 run 했을 때 example 모델에 의해 생성된 테이블이다.
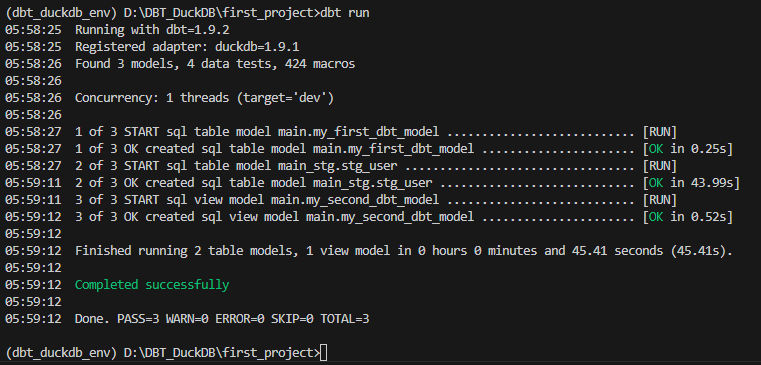
dbt run을 실행하면 다음과 같은 결과가 출력된다.
용량이 3.3GB정도 되는 yelp_academic_dataset_user.json 파일이 stg_user 테이블에 정해진 모델대로 들어가는데 43.99초가 소요되었다.
dbt run 후의 DB 상태는 DBeaver로 봤을 때 다음과 같다.
이번에 추가한 stg_user.sql 파일에 적힌 모델대로 main_stg 스키마에 stg_user 테이블이 추가되어있다.
stg_user.sql 파일 상단의 config에서 schema='stg'라고 썼어도 실제 생성되는 스키마의 이름은 main_stg로 된다.
데이터를 조회 해보니 다음과 같은 형식을 가지고 있다.

yelping_since 날짜별로 구분된 데이터를 보고싶어서 다음과 같이 모델을 작성했다.
파일의 모든 데이터를 불러오지 않고 필요한 필드만 선택해서 읽도록 수정했다.
-- models/stg/stg_user.sql 파일 수정
{{ config(
schema='stg',
materialized='table'
) }}
WITH yelp_academic_dataset_user AS (
select yelping_since, user_id, review_count, useful, funny, cool
from read_json('D:\\DBT_DuckDB\\data\\yelp_academic_dataset_user.json')
)
SELECT *
FROM yelp_academic_dataset_user
yelping_since 날짜별로 group by하는 모델을 만드는데 이미 만들어진 stg_user 모델의 데이터를 사용하기 때문에
{{ ref('stg_user') }} 로 모델을 참조한다.
-- models/mid/mid_yelping_since.sql 파일 작성
{{ config(
schema='mid',
materialized='table'
) }}
WITH mid_yelping_since AS (
select strftime(yelping_since,'%Y-%m-%d') as sincedate
, count(user_id) as userCnt
, count(distinct user_id) as uidCnt
, sum(review_count) as reviewCnt_sum
, sum(useful) as usefull_sum
, sum(funny) as funny_sum
, sum(cool) as cool_sum
from {{ ref('stg_user') }}
group by sincedate
order by sincedate
)
SELECT *
FROM mid_yelping_since
수정 후 dbt run 결과는 다음과 같다.
데이터 파일에서 데이터 전부를 가져오지 않아서 그런지 stg_user 모델 실행에 25.21초밖에 걸리지 않았고 이후 mid_yelping_since 모델도 실행되는걸 볼 수 있다.
100만 건이 넘는 데이터를 날짜별로 group by 하는데 0.62초 소요되는 건 굉장히 빠른 것 같다.

[ 테스트 만들기 ]
위의 mid_yelping_since 모델을 만들면서 같은 user_id 필드를 count할 때 distinct 조건을 추가하느냐에 따라 userCnt와 uidCnt 필드를 나눠서 집계했다.
데이터 파일에 한 유저당 하나의 데이터만 있다는 전제라면 두 값이 동일해야 하는데 혹시 그렇지 않다면 오류가 나타나도록 테스트를 작성할 수 있다.
first_project/model/tests/ 경로에 test_uid_uniqe.sql 파일을 작성한다.
-- models/tests/test_uid_uniqe.sql
select *
from {{ ref('mid_yelping_since') }}
where uidCnt <> userCnt
테스트 작성완료 후 dbt test 명령어로 실행할 수 있다.
다음과 같은 결과로 not_null_my_first_dbt_model_id는 실패하는 경우의 example로 넣어준 것 같다.
내가 이번에 추가한 test_uid_uniqe는 PASS되었다.
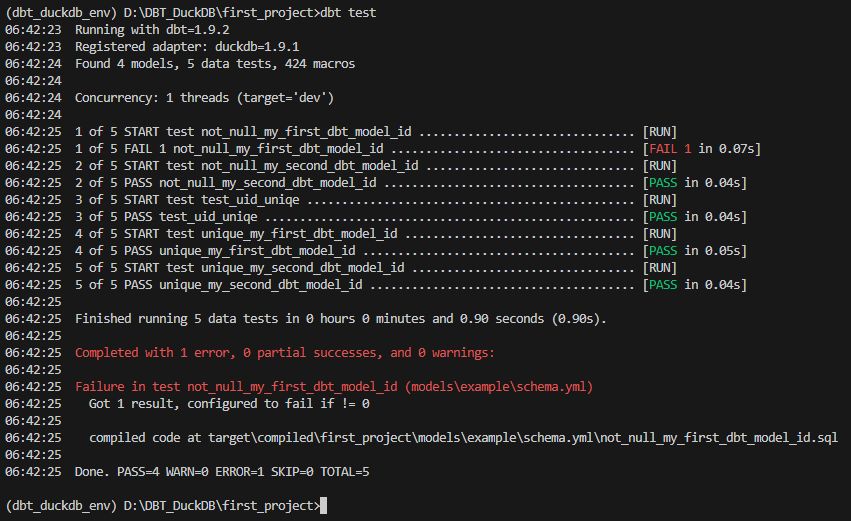
test를 만들 때는 해당 쿼리로 데이터가 조회되면 FAIL이므로 나오면 안되는 조건의 데이터를 조회하도록 하면 된다.
[ Docs ]
이렇게 dbt로 데이터 파이프라인을 다루면 run 명령어 한번으로 데이터 읽기부터 집계까지 전부 빠르게 해주니 좋다.
추가로 dbt를 활용하면 좋은 점은 docs 기능이다.
모든 모델들이 run된 후에 다음 명령어를 실행하면 웹이 하나 열린다.
# 문서 생성
dbt docs generate
# 문서 조회
dbt docs serve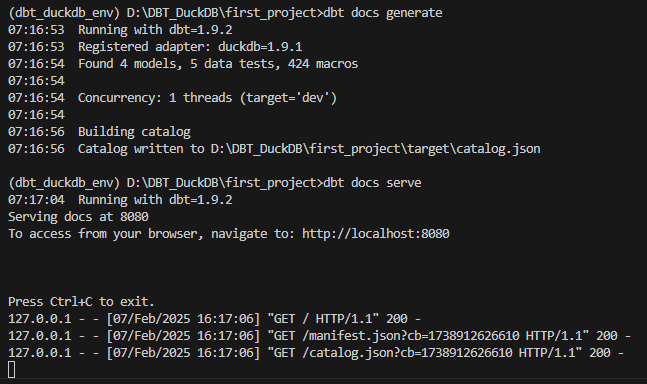

여기에서 왼쪽의 사이드바를 보면 모델과 테스트들이 어떻게 생성되어있는지, 데이터베이스 구조는 어떠한지 확인할 수 있다.
오른쪽 하단의 파란 버튼을 누르면 각 모델과 데이터 사이의 종속성을 확인할 수 있는 도표가 그려진다.(전에는 이걸 모든 타이틀에 대해 그리느라 고생했었는데..)

[ 그 외 ]
그 외에도 다양한 기능들이 있지만 일단 지금 내가 필요할 것 같은 기능은 이정도인 것 같아 여기까지 실습해봤다.
seed 기능도 써보려고 했는데 아쉬웠던 점은 csv 파일에 한글이 포함되면 인코딩 에러가 발생한다는 것이다.
json 파일에 있는 한글은 문제없는 것 같다.
DuckDB는 접속을 여럿이 못한다는 단점이 있으니 데이터 집계에만 사용하고 마트까지 집계 완료된 데이터를 MySQL이나 PostgreSQL로 옮겨서 BI에 활용하는 방식은 어떨까 싶다.
'하는 일 > 데이터엔지니어링' 카테고리의 다른 글
| [ 따라잡기 ] 현대적인 파이썬 프로젝트 준비 - uv 활용 dbt 프로젝트 준비 (0) | 2025.04.11 |
|---|---|
| [ 따라잡기 ] DuckDB + DBT 데이터 파이프라인 만들기 (3) - DBT Models (0) | 2025.02.07 |
| [ 따라잡기 ] DuckDB + DBT 데이터 파이프라인 만들기 (1) - DuckDB (0) | 2025.02.07 |
| [Medium 아티클] Data Landscape Trand 2024-2025 (0) | 2025.02.04 |
| [아티클] 최근 관심있는 분야의 글이 많은 블로그 (0) | 2025.01.21 |



